前言
SSTable就是把一个跳表放入一个文件,但是我们不仅仅是把KeyValue写入文件就结束了,还需要做一些其他的事:
- 写入KV
- SSTable的一些元信息,如最大Key,最小Key,KV的个数等。
- 为KV维护一定的索引,加速查找
- 进行一定比例的数据压缩
- 数据完整性校验
文件的大体格式如下:

文件的格式大致分为一个一个的Block
- Data Block存储的是数据,就是KV。
- MetaIndex Block
- Index Block
- Footer
其中在源码中,DataBlock是大头,2和3叫Footer。
MetaIndex在Java版本的实现中是个空Block。
这三个Block的底层实现都是BlockBuilder,BlockBuilder是个存储KV的格式。
个人感觉上其实BlockBuilder是为了DataBlock打造的,而IndexBlock只是恰好复用了一下。
所以下文将的DataBlock其实就是DataBlock的机制。
DataBlock
BlockBuilder的切分是根据每个Block的大小定的。
当一个Block的大小超过4 * 1024,也就是4M的时候,就会阶段,重启一个Block。
在Block内部的数据,也不是全部堆在一起,而是分为一组一组的,叫做DataGroup(非官方定义,我定的名字)。
分组个数是固定的,根据配置的blockRestartInterval来,默认是16个KV一组。
为什么要进行分组呢,其实这里要提一下写入数据时的压缩。
比如连续的两个Key,”the car”和”the car window”,他们有共同的前缀”the car”,对于这个前缀,我们可以只写入一份来起到数据压缩的效果。
如果我们不分组,那么我们找到一个Key,想知道他原来的Key是啥,得遍历前面所有的Key,这是不现实的。
所以每隔16个KV,我们就从头开始存储,不计算与之前的Key的共同前缀了。
假设我们put三个Entry,三个InternalKey如下:
1 | 1. userKey=foo123, seq = 3, type=VALUE, value = "fvdnvfdn" |
写SSTable了,真正写入的Bytes,会对InternalKey调用encode方法
1 | public Slice encode() { |
大致就是把seq + valueType拼成一个Long类型,和userKey合在了一起。
写入一个KV的操作基本流程如下:
1 | int sharedKeyBytes = calculateSharedBytes(key, lastKey); // 1 |
这里我们以
1 | 1. userKey=foo123, seq = 3, type=VALUE, value = "fvdnvfdn" |
这两个KeyValue为例,假设foo123已经被写入了,就是lastKey,当前的Key=foo456,其实实际上不是这样的,这里实际拿到的值已经被拼了末尾的Long类型进去,这里为了好解释。同时写入数值也会做相应的转换,这里先忽略。
foo123和foo456的sharedKeyBytes,也就是开始的foo,数值为3nonSharedKeyBytes也即是456,数值也是3- 这一步写入
sharedKeyBytes值到文件中,文件内容变成3 - 写入
nonSharedKeyBytes,文件内容为3 | 3 - 写入Value的长度,文件内容变成
3 | 3 | 8 | - 写入非共同前缀的字符也就是456,文件内容为
3 | 3 | 8 | 456 | - 写入Value的值,文件内容为
3 | 3 | 8 | 456 | fvdnvfdn
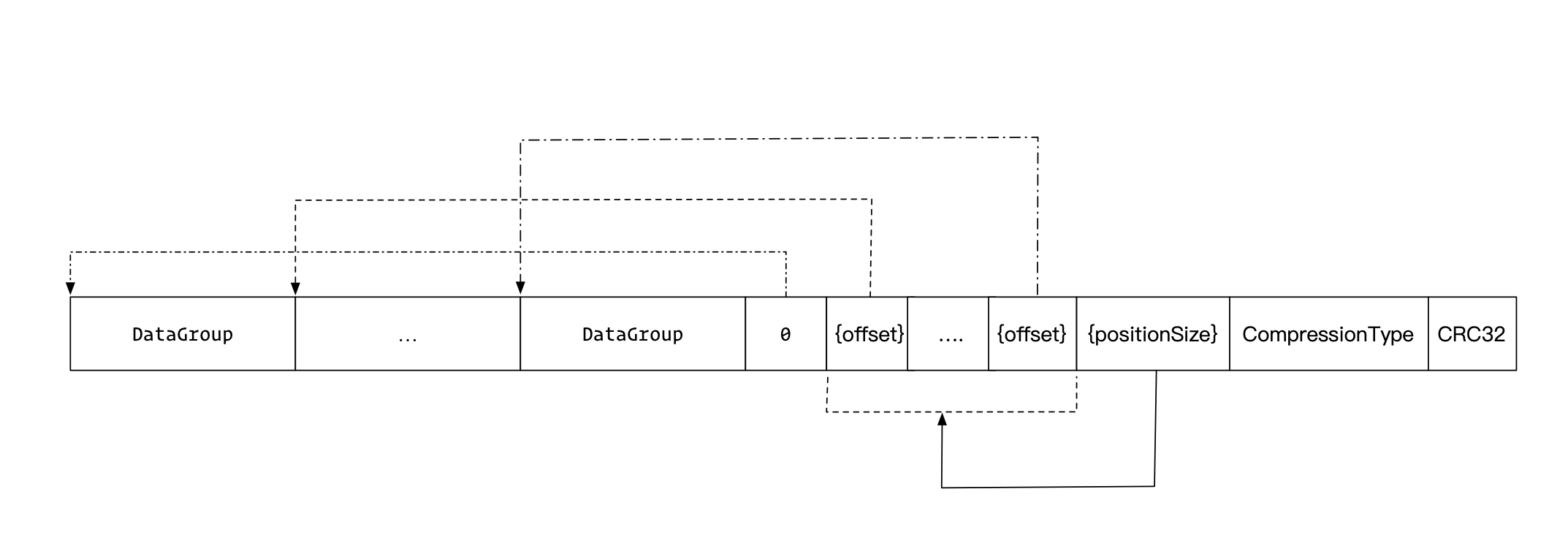
所以整体来看,一个DataGroup中每行Record的数据如下:

前面提到,每个DataGroup有16行,超过16行之后,就会置LastKey为空,然后下一行开始的sharedKeyBytes就是0,nonSharedKeyBytes就是当前Key的完整长度。
下面就要为每个DataGroup建立索引,记录每个DataGroup的开始位置。
变量restartPositions就是为这个索引准备的。
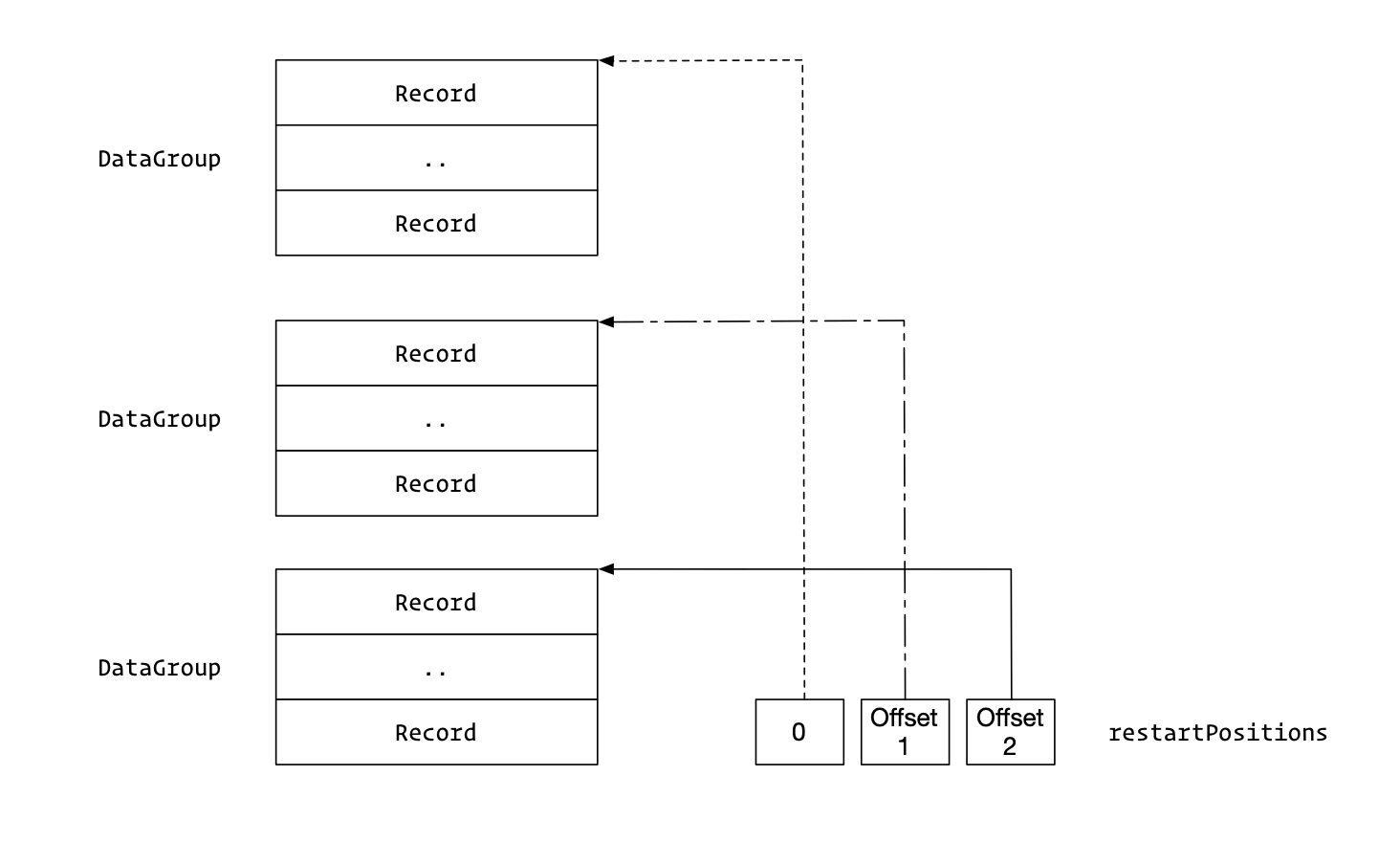
第一个DataGroup的位置就是0。
数据写完之后,把每个DataGroup的开始Offset写入到这个Block中。
看源码:
1 | public Slice finish() |
数据写完后,如果符合压缩条件,还要进行数据压缩。
最后补上Trailer,Trailer就一个Byte和一个Int,Byte表示压缩方式,Int表示对数据的CRC32,用来验证数据完整性。
最后整个DataBlock的数据如下:
Index Block
Index Block的内容每次写入一个DataBlock都会新增。
这里的代码其实还比较绕人,主要是findShortestSeparator这个方法。
让我们先抛开源代码,想一想对DataBlock建立索引需要记录哪些信息。
- 最大Key,最小Key
- KV的个数
- StartOffset,EndOffset
先来看看最大Key和最小Key的问题。
建立这个索引,主要是为了搜索Key,和最大的比较和最小的比较一下,就能知道是否在这个DataBlock中。
那么
问题1:是否需要最小Key?看源码,是Index Block中并没有存。
问题2:是否需要最大Key?是需要的,不过这里并没有存最大Key是什么。为什么?
或者我们再反问一句,存最大Key的意义是为了记录这个DataBlock里面的数据的边界,如果我们存储比MaxKey稍大一点的Key是不是也是同样的效果呢?
举个例子:MaxKey = helloworld,下一个Block的最小Key是hellozoomer,那么我们存储hellox,是不是可以起到同样的效果呢?
这就是方法findShortestSeparator的功能。
算出来一个Key,这个Key > MaxKey && Key < nextBlockFirstKey。能够起到和MaxKey一样的作用,同时存储时能够压缩空间。
解决了问题2,我们再来看看问题1,为啥IndexBlock中没有存MinIndex,我感觉是这样
又不是不能用。
shortestSeparator既可以表示前一个Block的MaxKey,又可以表示后一个Block的MinKey
IndexBlock复用的DataBlock的格式,存储MinKey不太方便
按照上面一个观点,其实一个DataBlock中的KV的个数,在IndexBlock中也没有存储。
其实如果我们看到后面那个,BlockIterator::seak方法,进行二分查找的时候,是直接seek到那个位置,然后读取出第一个Key的。
下面看看IndexBlock的存储。
每写完一个DataBlock,会返回这个DataBlock的两个数值
- offset:在文件中的offset
- dataSize:block的存储长度
在IndexBlock中,将shorttestSeparator作为key,(offset + dataSize)统一作为Value,构造出一个KV的结构放进去。
其实IndexBlock和DataBlock底层都是BlockBuilder的实现。
所以IndexBlock的格式和DataBlock是一样的。
MetaIndex Block
我看Java版本的实现中是个空Block。
Footer
Footer主要是为了记录MetaIndexBlock和IndexBlock的位置信息和一些填充字段和MagicWord。
直接上源码:
1 | public static void writeFooter(Footer footer, SliceOutput sliceOutput) |
- 写入MetaIndexBlock的位置信息(offset + size)
- 写入IndexBlock的位置信息(offset + size)
- padding
- MagicNumber
Table的读取和iterator
对SSTable的读取,需要传入的是SSTable的fileChannel,然后进行初始化:
1 | public Table(String name, FileChannel fileChannel, Comparator<Slice> comparator) { |
- seek到文件的尾部,把MetaIndexBlock的位置信息 + IndexBlock的位置信息读取出来
- 把IndexBlock的信息全部读取到内存中来
因为DataBlock和IndexBlock的底层都是Block,所以这里先提一下对Block的迭代方法:
实现类是BlockIterator
再回顾下之前的Block的格式
数据每16个KV一组分为DataGroup,在Block的尾部记录每个DataGroup的位置信息,也就是重启点位置。
这里的迭代分几个重要的点:
- 重启点的信息可以全部在初始化的时候就反序列化成数组
- 遍历DataGroup的KV时,需要记录上一个Key的原始值,不然不好恢复出当前Key的值
- 二分搜索时,转化成对RestartPositions数组的二分搜索
讲完了对Block的迭代,下面讲讲对SSTable的迭代
对SSTable的迭代在方法Table::iterator中
方法的实现如下:
1 | public TableIterator iterator() |
这里的TableIterator的实现思想和Block的迭代的实现思想差不多。
IndexBlock的KV,是对前面DataBlock的【分割Key】+ 位置信息的保存。
所以这里的TableIterator的实现思想是:
- 遍历时,转化成对IndexBlock和DataBlock的双层遍历。
- 每次读取一个DataBlock在内存中。如果当前DataBlock遍历结束,就从IndexBlock读取下一个DataBlock的位置,seek到那个位置,把下一个DataBlock全部读取到内存中,再对这个DataBlock进行遍历。
- 二分查找,先对IndexBlock进行二分查找,找到【分割Key】的所在的DataBlock的位置信息,然后再读取改DataBlock,在这个DataBlock中进行二分搜索。
